
Иногда, решая задачи на программирование на Степике, учащиеся сталкиваются с интересной проблемой, которая очень неочевидна и как бы не видна. Но она есть и заставляет периодически шевелить мозгами в попытках понять, а что же пошло не так? В данной статье я постараюсь объяснить, что же именно пошло не так.
Представим себе задачу. Нужно что-то сделать и затем вывести на экран какой-то текст. Человек пишет код решения. Ему кажется, что все правильно. Он отправляет решение на проверку и неожиданно видит следующее:



Возникает закономерный вопрос: «В чем же проблема?» Действительно, кажется, будто текст, который должен быть выведен и тот, который вывело решение учащегося одинаковы.
Тот, кто читал мою статью Строки в программировании — невнимательность и кодировки, или просто в теме, может сказать, что все очевидно — где-то попал кириллический символ в строку с латиницей. Визуально нам кажется, что строки одинаковы, но для компьютера кириллические и латинские символы являются разными. Даже если выглядят идентично.
И этот человек окажется не прав. По крайней мере в этом случае. Сравниваем текст правильного вывода и вывода учащегося, используя специальные инструменты и видим, что тексты полностью идентичны:

В этот момент может начаться паника. Как же так, в чем же проблема и что делать?
Спокойствие, главное спокойствие. Тексты действительно отличаются. Просто из-за особенностей работы буфера обмена браузера некоторые символы в процессе копирования теряются (не спрашивайте меня как это работает, я не в курсе). В нашем случае это невидимый символ неразрывного пробела. Чтобы убедиться, что он там действительно есть, копируем из логов ошибки задачи наши строки под «Your code output:», например, в Word. Там включаем отображение всех символов и видим следующую картину:
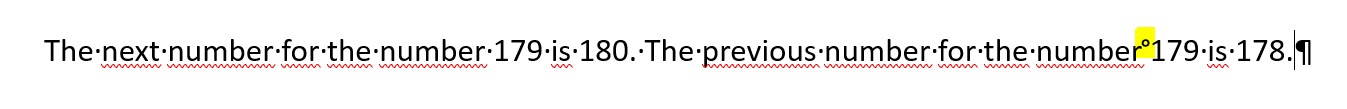
Видите мааааленький кружочек, который я выделил желтым на скриншоте? Вот это и есть наш неразрывный пробел, который каким-то образом попал в строку и ломает проверку нашего отправленного решения. Так как для компьютера тексты РАЗНЫЕ. В правильном ответе обычные пробелы. А в отправленном нами затесался ненужный символ — неразрывного пробела.
Достаточно его убрать, заменив обычным пробелом и решение пройдет проверку и будет засчитано.
Обычно такая ошибка проявляется при решении задач с использованием языка программирования PHP. Почему так — я не знаю. Но, имейте ввиду.
Удивительно рядом. Иногда оно еще и невидимо. Но мы то выведем такие ошибки и неточности на чистую воду. Так что учитесь, решайте задачи и будьте внимательны. Как видите, существует множество мелочей, которые хотя и кажутся незначительными, но могут здорово потрепать наши нервы в попытках выяснить, а что же пошло не так?